Published on
JSON vs. XML: A Data-Driven Analysis of LLM Parsing Efficiency
Methodology Note: This analysis was conducted by an independent developer as a personal project to answer real-world implementation questions. I am not a professional academic researcher and am not affiliated with any of the companies whose models were tested. All tests used publicly available chat interfaces—the same interfaces developers and businesses actually use—rather than sterile API conditions. We tested 5 runs per condition, which exceeds typical industry evaluation practices while remaining resource-efficient. This work has not been formally peer-reviewed and prioritizes practical applicability over academic formalism. All data, prompts, and automated evaluation scripts are available in our GitHub repository for full transparency and replication.
Update (Aug 6, 2025): Expanded the study to 12 models across 8 companies, including the newly released GPT-OSS variants, Claude-4.1-Opus, and additional models from Google, DeepSeek, Zhipu AI, Kimi, and Qwen. The results, verified by an automated evaluation script, reveal clear, company-level architectural patterns.
Abstract
While the AI developer community widely defaults to JSON for structuring data within LLM prompts, growing debates question whether this convenience comes at a cost. Critics cite token overhead and potential quality degradation, but these concerns have remained largely theoretical. This study moves beyond speculation to provide empirical evidence on a more critical metric: accuracy and instruction adherence. We subjected 12 leading LLMs to a creative task using identical hybrid prompts—natural language instructions followed by either JSON or XML data. Our findings reveal that format preferences are strongly tied to model architecture. Anthropic models show a consistent and powerful XML advantage, while Google and Kimi models prefer JSON. However, the most sobering discovery is that raw model capability is the dominant factor: a significant portion of the tested models failed both formats on this complex, multi-constraint task.
1. The Problem: Do JSON Data Structures Hinder LLM Performance?
While JSON has become the de facto standard for structured data in LLM prompts—treated almost as a “native language” for models trained on vast code repositories—this assumption is increasingly being challenged. The hybrid approach of embedding JSON within natural language instructions, though widespread, may not be optimal.
The criticism on X centers on JSON’s “symbol noise” inefficiency: the braces, quotes, and commas that critics argue can overwhelm models when parsing complex structured data, leading to performance degradation. Yet despite these theoretical concerns, empirical testing of alternatives like XML remains limited.
This study was designed to answer a focused question: In hybrid prompts that combine natural language instructions with structured data, which data format leads to higher accuracy and better instruction adherence across different model architectures?
2. Methodology: A Replicable, Automated Test for Creative Integration
To provide a definitive answer, we designed a rigorous, replicable experiment focused on creative output, not simple data extraction.
-
Objective: To measure an LLM’s ability to accurately parse and incorporate all structured elements from a data block into a coherent narrative while following strict formatting constraints.
-
Task: The LLM was instructed to act as a “creative storyteller” and generate a short, dialogue-heavy fantasy story (200-300 words) based on provided character profiles, starting and ending with specific phrases.
-
Dataset (Character Profiles): We used a set of three interconnected characters designed to test relational reasoning and constraint adherence:
- Elara: brave elf archer, loyal to Thorne, carries a magic bow.
- Thorne: wise wizard, mentor to Elara, rival of Draven, carries an enchanted staff.
- Draven: cunning dragon rider, rival of Thorne, seeks a hidden treasure, carries a fire sword.
-
Models Tested: We evaluated 12 models across 8 major AI companies:
-
Hybrid Prompts: Each model was tested 5 times with each format for a total of 120 runs. The prompts combine natural language instructions with structured data sections:
JSON Prompt:
You are a creative storyteller in a chat. A user has provided character profiles in JSON format for a fantasy story. Generate a short story (exactly 200-300 words) that incorporates ALL details from the profiles into a dialogue-heavy narrative. Start with: "Once upon a time in the enchanted forest..." End with: "And so, the adventure continued." Do not add, omit, or change any details. Output ONLY the story. { "characters": [ { "name": "Elara", "trait": "brave elf archer", "relationship": "loyal to Thorne", "item": "magic bow" }, { "name": "Thorne", "trait": "wise wizard", "relationship": "mentor to Elara, rival of Draven", "item": "enchanted staff" }, { "name": "Draven", "trait": "cunning dragon rider", "relationship": "rival of Thorne", "item": "fire sword", "goal": "seeks a hidden treasure" } ] }XML Prompt:
You are a creative storyteller in a chat. A user has provided character profiles in XML format for a fantasy story. Generate a short story (exactly 200-300 words) that incorporates ALL details from the profiles into a dialogue-heavy narrative. Start with: "Once upon a time in the enchanted forest..." End with: "And so, the adventure continued." Do not add, omit, or change any details. Output ONLY the story. <characters> <character> <name>Elara</name> <trait>brave elf archer</trait> <relationship>loyal to Thorne</relationship> <item>magic bow</item> </character> <character> <name>Thorne</name> <trait>wise wizard</trait> <relationship>mentor to Elara, rival of Draven</relationship> <item>enchanted staff</item> </character> <character> <name>Draven</name> <trait>cunning dragon rider</trait> <relationship>rival of Thorne</relationship> <item>fire sword</item> <goal>seeks a hidden treasure</goal> </character> </characters> -
Automated Evaluation & Scoring: To ensure objectivity and replicability, we developed a Python evaluation script (
evaluate.py). For each of the 120 runs, a “Full Success” was awarded only if the output met all criteria after text normalization (lowercase, standard quotes):- Formatting: Must contain the required start/end phrases and be within the 200-300 word count limit.
- Data Integrity: Must contain all 13 key elements from the character profiles (e.g.,
brave,mentor,magic bow).
An output failing any single check was not considered a “Full Success.”
3. Results: Company-Level Architecture Patterns Emerge
The script-verified results from 120 test runs reveal clear architectural preferences at the company level.
Individual Model Performance
The individual model results reveal dramatic performance variations that extend far beyond simple format preferences. While some models like Grok-3 achieved perfect scores regardless of format, others struggled significantly with structured data parsing entirely.
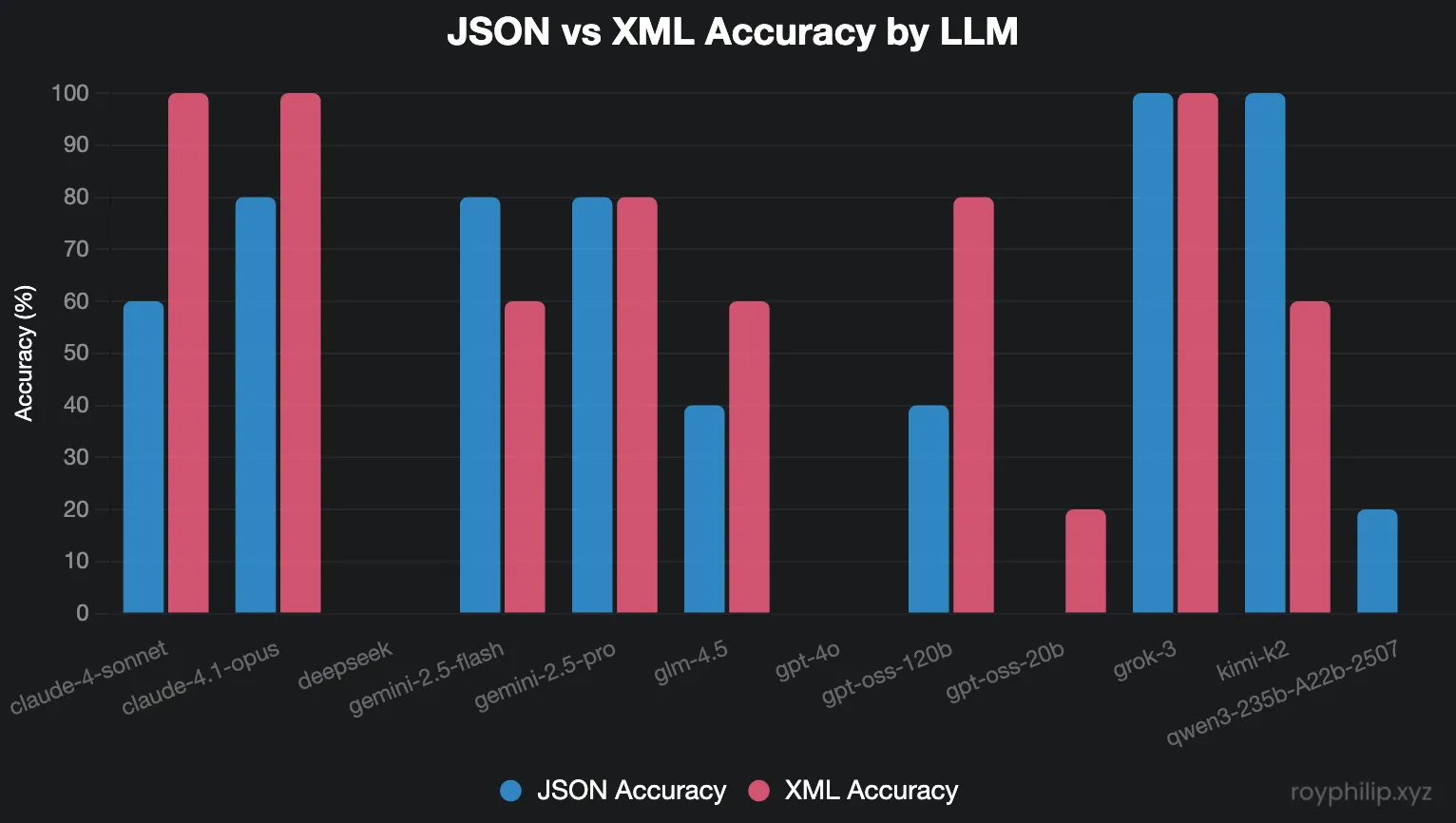
| LLM | Format | Runs | Success | Accuracy Rate | Most Common Errors (from detailed logs) |
|---|---|---|---|---|---|
| claude-4-sonnet | json | 5 | 3 | 60.00% | Missing: ‘mentor’ |
| claude-4-sonnet | xml | 5 | 5 | 100.00% | None |
| claude-4.1-opus | json | 5 | 4 | 80.00% | Missing: ‘mentor’ |
| claude-4.1-opus | xml | 5 | 5 | 100.00% | None |
| deepseek | json | 5 | 0 | 0.00% | Word count, Missing: ‘mentor’, ‘rival’ |
| deepseek | xml | 5 | 0 | 0.00% | Word count, Missing: ‘mentor’, ‘rival’ |
| gemini-2.5-flash | json | 5 | 4 | 80.00% | Missing: ‘hidden treasure’ |
| gemini-2.5-flash | xml | 5 | 3 | 60.00% | Word count, Missing: ‘mentor’ |
| gemini-2.5-pro | json | 5 | 4 | 80.00% | Word count |
| gemini-2.5-pro | xml | 5 | 4 | 80.00% | Missing: ‘mentor’ |
| glm-4.5 | json | 5 | 2 | 40.00% | Word count, Missing: ‘mentor’ |
| glm-4.5 | xml | 5 | 3 | 60.00% | Word count, Missing: ‘hidden treasure’ |
| gpt-4o | json | 5 | 0 | 0.00% | Multiple missing keywords |
| gpt-4o | xml | 5 | 0 | 0.00% | Multiple missing keywords |
| gpt-oss-120b | json | 5 | 2 | 40.00% | Missing: ‘mentor’, ‘wise’ |
| gpt-oss-120b | xml | 5 | 4 | 80.00% | Missing: ‘mentor’ |
| gpt-oss-20b | json | 5 | 0 | 0.00% | Multiple missing keywords |
| gpt-oss-20b | xml | 5 | 1 | 20.00% | Missing: ‘mentor’, ‘rival’, ‘cunning’ |
| grok-3 | json | 5 | 5 | 100.00% | None |
| grok-3 | xml | 5 | 5 | 100.00% | None |
| kimi-k2 | json | 5 | 5 | 100.00% | None |
| kimi-k2 | xml | 5 | 3 | 60.00% | Missing: ‘mentor’ |
| qwen3-235b-A22b-2507 | json | 5 | 1 | 20.00% | Word count, Multiple missing keywords |
| qwen3-235b-A22b-2507 | xml | 5 | 0 | 0.00% | Word count, Multiple missing keywords |
These individual results become even more compelling when aggregated by company, revealing clear architectural patterns that suggest deep training and design philosophy differences.
Company-Level Analysis
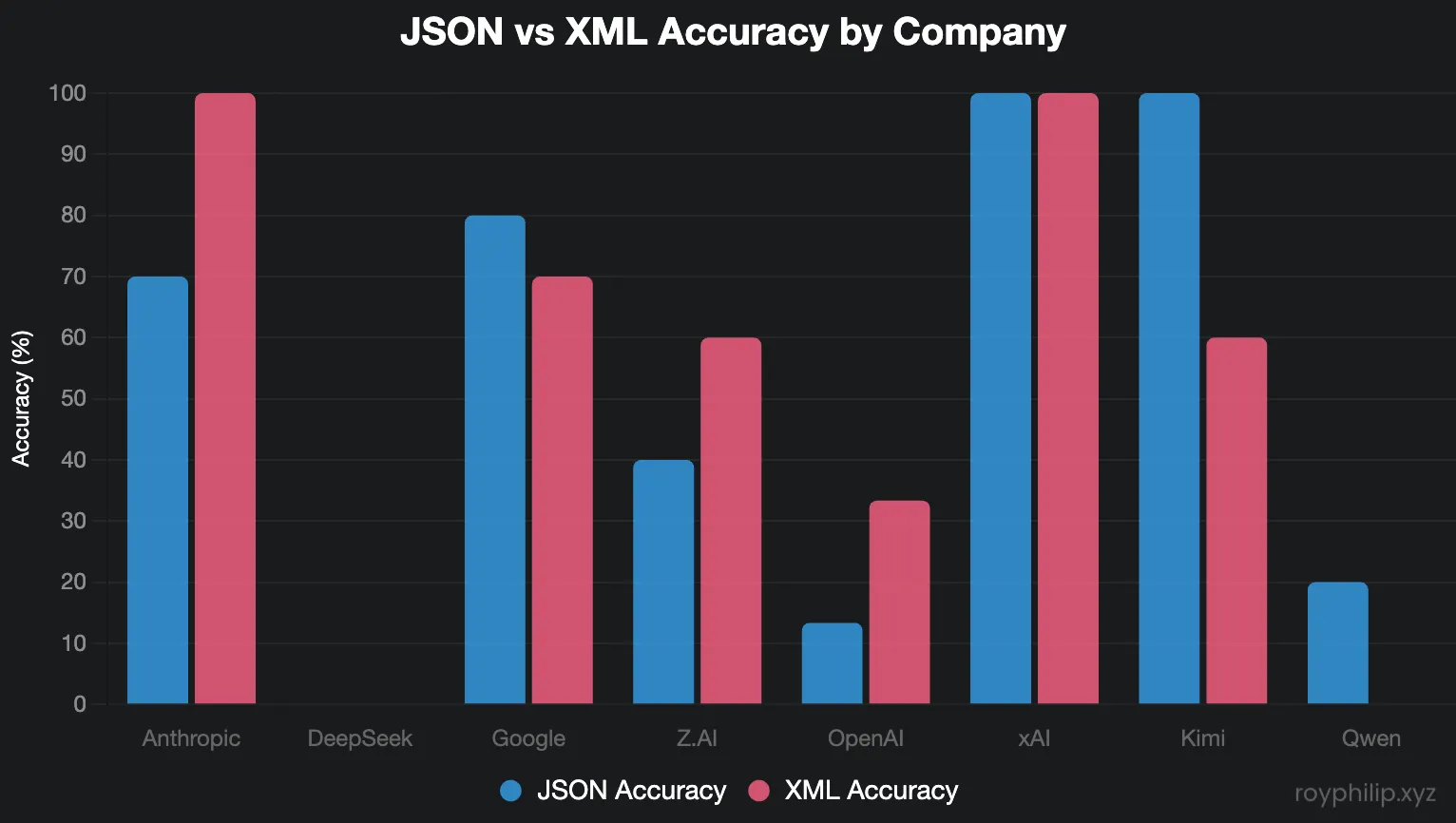 Company-level performance comparison showing clear architectural preferences. Note: DeepSeek, Qwen, and GPT-4o showed near-total failure on this task.
Company-level performance comparison showing clear architectural preferences. Note: DeepSeek, Qwen, and GPT-4o showed near-total failure on this task.
| Company | JSON Avg | XML Avg | Preference | Advantage | Models Tested |
|---|---|---|---|---|---|
| xAI | 100% | 100% | Neutral | +0% | 1 |
| Kimi | 100% | 60% | JSON | +40% | 1 |
| 80% | 70% | JSON | +10% | 2 | |
| Anthropic | 70% | 100% | XML | +30% | 2 |
| Zhipu AI | 40% | 60% | XML | +20% | 1 |
| OpenAI | 13% | 33% | XML | +20% | 3 |
| Qwen | 20% | 0% | JSON | +20% | 1 |
| DeepSeek | 0% | 0% | Neutral | +0% | 1 |
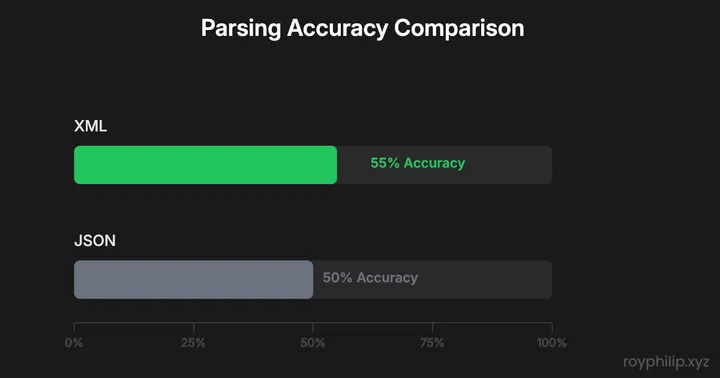
The industry-wide statistics tell a sobering story: even with format optimization, substantial portions of the tested models failed to handle complex structured reasoning tasks.
Overall Industry Performance
| Format | Total Runs | Full Successes | Overall Accuracy |
|---|---|---|---|
| XML | 60 | 33 | 55.00% |
| JSON | 60 | 30 | 50.00% |
4. Analysis & Discussion
The data reveals a clear hierarchy of factors affecting LLM performance on structured tasks.
Model Capability is Paramount. Before any format discussion, the underlying model must demonstrate basic competence. Models like GPT-4o, DeepSeek, and Qwen failed almost completely regardless of format, proving that no amount of prompt optimization can fix fundamental reasoning limitations. This finding reshapes the entire debate—format choice is irrelevant if the model cannot handle structured constraint-following tasks.
Building on this foundation, Company Architectures Dictate Format Preference among capable models. The most significant finding is that format efficiency clusters by provider rather than individual model characteristics, suggesting deep architectural differences in training and design philosophy:
-
Anthropic’s XML Dominance: Both Claude models showed a massive +30% accuracy boost with XML, moving from good (70%) to perfect (100%) performance. This consistent pattern suggests their architecture is optimized for explicit tag-based parsing.
-
The JSON Champions (Kimi & Google): Kimi demonstrated a staggering +40% advantage with JSON, while Google’s models showed a smaller but consistent +10% JSON preference. These architectures appear tuned for the nested structure and key-value parsing of JSON.
-
The Format Agnostic (xAI): Grok-3 stands alone as the only model achieving perfection with both formats, demonstrating an architecture robust enough to transcend syntax preferences entirely.
OpenAI’s Structured Data Challenge emerges as a concerning pattern. The flagship GPT-4o completely failed this test (0% success rate), while even the improved OSS variants struggled significantly compared to top-tier competitors. This suggests architectural limitations in complex structured data integration tasks.
These architectural preferences appear consistent across model generations within each company, indicating that format optimization strategies should be chosen based on provider rather than individual model updates.
5. Conclusion: It’s Not JSON vs. XML. It’s Your Model’s Architecture.
The debate over which format is “better” for LLMs is asking the wrong question. The data shows the correct question is: “Which format is better for the specific model architecture I am using?”
Key Takeaways:
-
Company-Level Patterns Are Real: Anthropic consistently prefers XML, Kimi prefers JSON, xAI is format-agnostic. These patterns likely reflect deep architectural differences in training and design.
-
Model Selection Trumps Format Optimization: Half the tested models failed both formats. Choosing a capable model matters more than optimizing data structure syntax.
-
Test Your Specific Stack: With such varied performance across companies, developers must empirically test their chosen models rather than relying on universal format recommendations.
Updated Actionable Recommendations:
- For Anthropic (Claude): Default to XML for structured data. The performance gain is significant and consistent.
- For Kimi and Google (Gemini): Default to JSON. It provides a clear accuracy advantage on these architectures.
- For xAI (Grok): Use whichever format you prefer. It excels with both.
- For OpenAI models: Consider alternative models for complex structured tasks
- For High-Stakes Tasks: If your task involves complex constraints, choose a model that demonstrated high capability first (Grok, Claude, Kimi, Gemini Pro), and only then optimize the format.
The format wars have revealed a map of the industry’s hidden architectural philosophies. In this landscape, the most valuable skill is not memorizing rules, but the ability to benchmark and adapt.
Raw data, test prompts, and the Python evaluation script are available in the project’s GitHub repository for full replication.